Java Virtual Machine (JVM) Architecture
Overview
A Java virtual machine (JVM) is a virtual machine that enables the computer to execute compiled bytecode. This was introduced in 1994 by Sun Microsystems. Virtual machines can be categorized into two sets.
- System Based Virtual Machine: One or more hardware systems that create multiple environments to work and those are completely independent.
- Application Based Virtual Machine: A software application that creates multiple platforms to run other programs. This is also known as a Process-Based Virtual Machine.
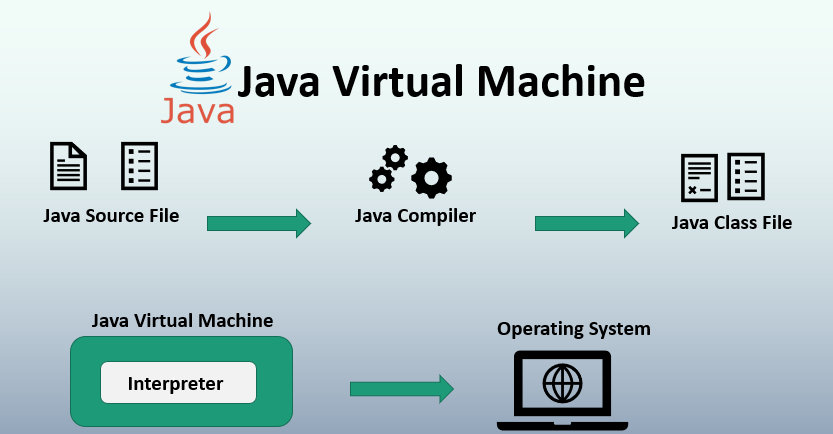
JVM is categorized under Application Based Virtual Machine. Mainly, Java Development Kit (JDK) comes with Java Runtime Environment (JRE) and when you install Java into your machine JRE deploys some codes to create instances of JVM based on the platform you use. Otherwise, you can get JRE instead of JDK but JDK is recommended for the developers since it provides facilities to compile the code and execute it. Figure 1. illustrates the general architecture of the JVM.

Generally, bytecode is in hexadecimal format with opcode-operand lines and an instance of JVM can interpret or compile this bytecode into machine-readable language. An instance of JVM is created after receiving the compiled bytecode using the javac compiler and this gets closed when all the non-daemon threads are closed inside the thread pool or the JVM instance calls the exit method while the program is running.
JVM Components

As in Figure 2, JVM is a composition of the class loader, memory area, and execution engine. Let’s clarify what each component does in detail.
Class Loader
This is the first component in the JVM and the class loader is responsible to perform many functions on the class file (.class) including, loading, linking, and initializing while verification, preparation, and resolution are performed at linking. So, let’s get into details about each function.
- Loading: When a class loader loads a class into the memory area, it reads some class-based information including, fully qualified class name, details about static variables/modifiers/method information, etc., type (enum/class/interface), and immediate parent. After that, this creates objects with class type per class and stores those created objects in heap.
- Linking: This performs functions called, verification, preparation, and resolution. At verification, ensure the validity of the compiler and correctness of the structure and format of the class file. These steps are performed by the bytecode verifier and if the class file fails to satisfy the above three conditions, the bytecode verifier throws a runtime error called java.lang.VerifyError. Next, preparation takes place and this assigns default values for the static members declared inside the class. Finally, at the resolution, replaces the user-defined references or objects with exact memory location addresses which are stored in heap.
- Initialization: This is responsible for initializing static variables with exact values and execute static blocks declared inside the class (if any). This process should complete before making the class active use.
Memory Area
As in Figure 3, this is a composition of method area, heap area, stack area, PC registers, and native method area. So, let’s clarify the purpose of each area.

- Method Area: This is a shared resource per JVM instance and JVM threads share this same memory area. Here, holds class information including field data, method data, variable size, etc.
- Heap Area: As method area, this is also created per JVM instance and this is responsible for holding information on objects created at the loading phase.
- Stack Area: This is not a shared resource. For every JVM thread, when a thread starts, a separate stack area is get created to store the information related to each method within the thread and their local variables as stack frames.
- PC Registers: This allocation is also get created per the JVM thread and this is responsible for holding the information about the methods of the next execution. But this only keeps the information about java methods and does not hold any information about native or other methods.
- Native Method Area: Native method area allocation is get created per thread and holds information about native methods (if any).
Execution Engine
The execution of the bytecode occurs here. This includes three main components for executing Java Classes.
- Interpreter: The job of this component is to read and convert bytecode into machine-readable code and execute each instruction one by one. Hence this can interpret the bytecode line quickly but takes much time to execute it.
- JIT Compiler (Just in Time Compiler): When one method calls multiple times, the interpreter needs to execute that particular instruction set repeatedly. This is time-consuming and slows down the execution process. To tackle this situation, the JIT compiler was introduced. JIT compiler directly converts the bytecode into native code (machine code) while performing certain simple optimization techniques including, keeping the compiled native codes of frequent instructions inside the cache. This is called adaptive compiling and this has been used in Oracle Hotspot VMs.
- Garbage Collector: This is a daemon thread that is responsible for freeing up the heap memory by destroying the unreachable objects declared inside the class. This gets activated when the heap is full.
In addition to these three components, there are another two components inside the JVM called Java Native Interface (JNI) and Native Method Libraries.
- Java Native Interface (JNI): This interacts with Native Method Libraries that are required for the execution and enables JVM to call them.
- Native Method Libraries: A collection of C/C++ Native Libraries that can be accessed through the provided Native Interface.
JVM Data Types
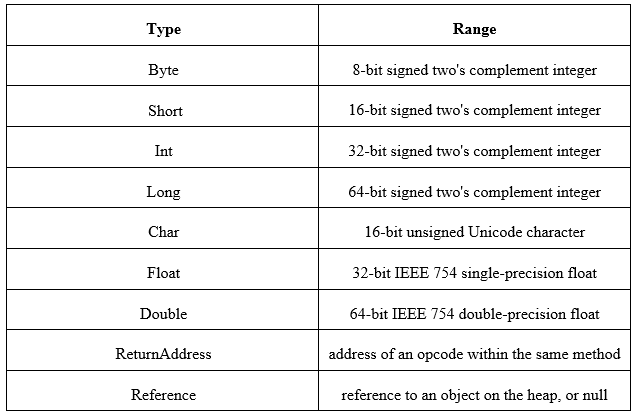
JVM performs computations on certain data, therefore data types and operations are strictly defined by the Java virtual machine specification. Figure 4. illustrates the classification of JVM data types.

Mainly, JVM data types can be divided into two sets as primitive and reference data types. In primitive data types, they hold the actual values themselves. But in reference data types, hold the reference of the object of that data type. When considering the Boolean data type, falsely represents using zero and truly represents by non-zero with the integer data type. But an array of Boolean symbols is represented using a single byte. ReturnAddress type is unavailable to the Java programmer and this primitive data type is used to implement finally clauses of Java programs. When considering reference type, class reference type holds the reference of class object located inside heap area. Interface reference holds the reference of the object of some class which implements the specific interface located inside heap area as class data type.
The basic unit of size for data values in the JVM is the word. The size of the word is decided by the designers of JVM implementation. Usually, a word must satisfy below two conditions.
- A word should be able to hold any primitive data type specified by JVM.
- Two words should be able to hold 64-bit double and long primitive data types.
Based on that, designers need to choose a word size with at least 32-bits to hold 64-bit length data types with two words. Table 1. Illustrates the ranges of data types in JVM.
Conclusion
As per the things discussed in the above topics, the main purpose of the JVM is to convert the bytecode into native code and execute it to get the output of the program. In this article, we have covered some facts related to JVM architecture, components, and data types.
References
